Abstract
Large language model (LLM) agents have shown remarkable capabilities in tackling complex, long-horizon problems. However, scaling agents to even longer horizons is fundamentally constrained by the design of agentic frameworks that linearly accumulate the entire interaction history into a single, ever-expanding context.
We propose Context-Folding, an agentic mechanism that allows the model to actively manage its working context. The agent can create temporary sub-trajectories for localized subtasks (branch), then summarize and rejoin the main thread (return), with intermediate steps being "folded" away. We also introduce FoldGRPO, a novel RL framework with dense, token-level process rewards that trains agents to effectively acquire this capability.
Our Folding Agent achieves 62.0% on BrowseComp-Plus and 58.0% on SWE-Bench Verified using only a 32K token budget, surpassing baselines requiring 327K contexts and significantly outperforming summarization-based methods.
Key Idea
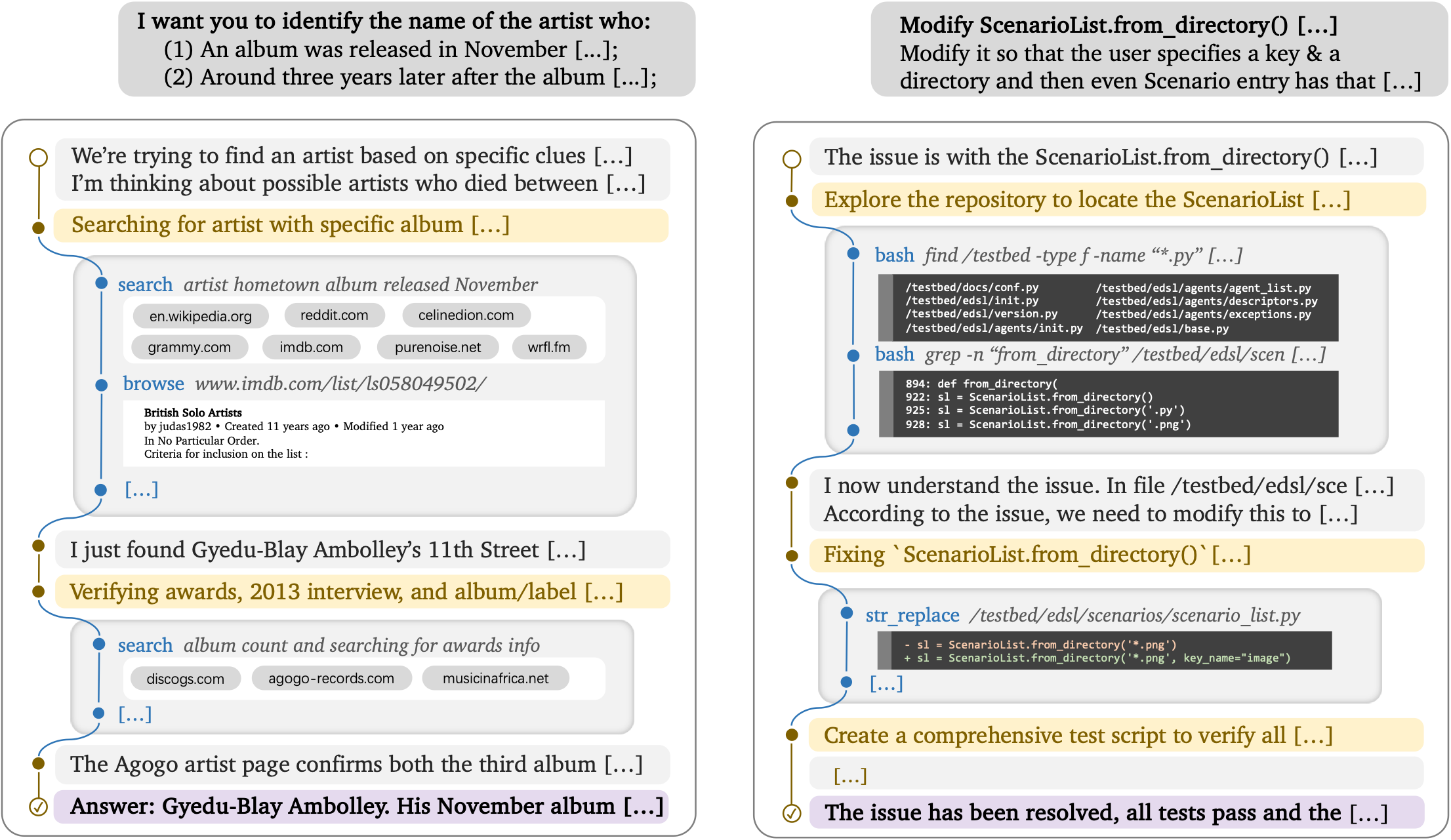
Example of an agent folding context in long-context tasks.
Method
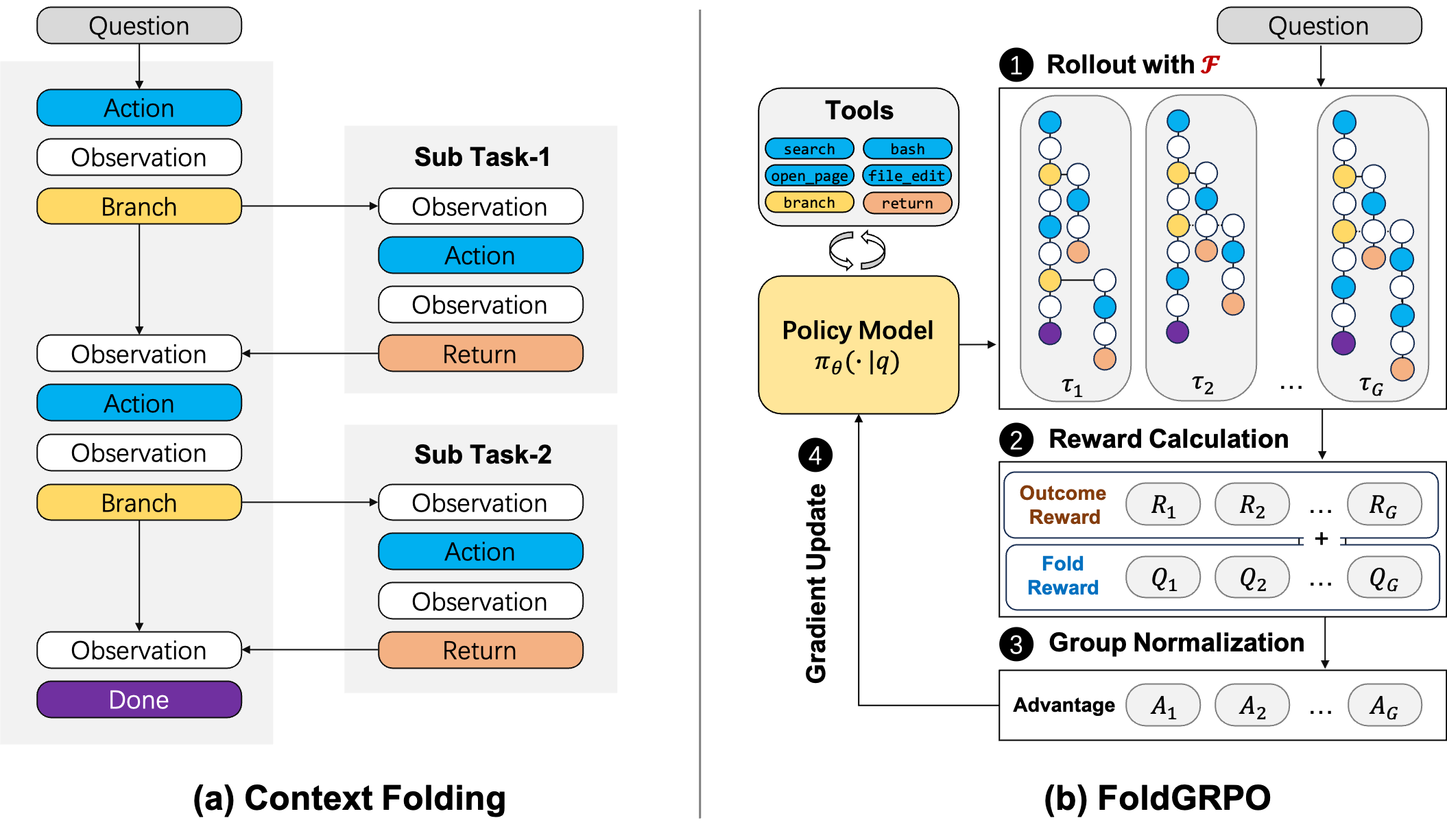
Overview of our Context-Folding framework and FoldGRPO training.
Results
Performance on BrowseComp-Plus (N=150) and SWE-Bench Verified (N=500)
| Model | Peak Length | Max Length | BrowseComp-Plus Pass@1 |
SWE-Bench Pass@1 |
|---|---|---|---|---|
| ReAct Agent with 100B+ LLM | ||||
| GPT-5 | 327K | 327K | 79.3% | 71.8% |
| GPT-4.1 | 327K | 327K | 64.0% | 48.6% |
| DeepSeek-V3.1 | 327K | 327K | 61.3% | 61.0% |
| GLM-4.5-Air | 327K | 327K | 56.6% | 57.6% |
| Qwen3-235B-A22B | 327K | 327K | 56.0% | 34.4% |
| ReAct Agent | ||||
| Seed-OSS-36B | 32K | 32K | 28.6% | 43.6% |
| + RL (GRPO) | 32K | 32K | 44.6% | 48.0% |
| Seed-OSS-36B (327K) | 327K | 327K | 47.8% | 55.2% |
| + RL (GRPO) | 327K | 327K | 54.0% | 57.4% |
| Summary Agent | ||||
| Seed-OSS-36B | 32K | 32K × 10 | 38.6% | 48.8% |
| + RL (GRPO) | 32K | 32K × 10 | 52.7% | 55.0% |
| Folding Agent (Ours) | ||||
| Seed-OSS-36B | 32K | 32K × 10 | 42.0% | 49.2% |
| + RL (GRPO) | 32K | 32K × 10 | 56.7% | 56.4% |
| + RL (FoldGRPO) | 32K | 32K × 10 | 62.0% | 58.0% |